name: empty layout: true --- name: base layout: true template: empty background-image: url(img/bg-white-simple.png) <div class="slide-footer">Tips and Tricks of the Docker Captains - @sudo_bmitch</div> --- name: title layout: true template: empty class: center, middle, left75 background-image: url(img/bg-city.png) --- name: inverse layout: true template: base class: center, middle, inverse background-image: none --- name: impact layout: true template: base class: center, middle, impact, right75 background-image: url(img/bg-scooter.png) --- name: picture layout: true template: base class: center, middle --- name: terminal layout: true template: base class: center, terminal background-image: url(img/bg-black.png) background-size: contain --- name: default layout: true template: base --- template: impact name: agenda # Agenda .content[.align-left[ .left-column[ - [Pruning](#prune) - [Cleaning Logs](#logs) - [Network Address Pools](#address-pools) - [Netshoot](#netshoot) ] .right-column[ - [Layers](#layers) - [Buildkit](#buildkit) - [Local Volume Driver](#volume-local) - [Fixing Permissions](#fix-perms) ] ] .no-column[ <br><br><br><br> ] ] --- template: empty class: title name: title # Tips and Tricks<br>Of The Docker Captains .content[ .left-column[ .pic-circle-70[] ] .right-column[.align-right[.no-bullets[ <br><br> - Brandon Mitchell - Twitter: @sudo_bmitch - GitHub: sudo-bmitch ]]] ] ??? - First started by Adrian Mouat, merged in my FAQ talk - My twitter and github handles are what any self respecting sysadmin does when you get a permission denied error on your favorite username. - This presentation is on github and I'll have a link to it at the end, I'll be going fast so don't panic if you miss a slide. --- template: default ```no-highlight $ whoami Brandon Mitchell aka bmitch - Solutions Architect @ BoxBoat - Docker Captain - Frequenter of StackOverflow ``` .align-center[ .pic-30[] .pic-30[] .pic-30[] ] ??? - BoxBoat is a Docker Business Partner that provides consulting services around containers - That's my mandatory plug so I can get my expense report reimbursed - Docker Captains is a recognition of community members spreading knowledge about docker. That may be blogs, training, speaking, or in my case... - I joined the Captains program after answering way too many StackOverflow questions. - I've answered almost 1.4k questions and gave a lightening talk at DC US on many of the common questions that is also up on github. --- template: inverse # Who is a Developer? ??? - Show of hands... I'm feeling a little outnumbered. - I'm one of the minority that came to docker from the Ops side. - Many of these tips will be Ops focused, but useful to everyone. --- template: impact .content[ # Disk Usage ] ??? - One of the common complaints is my harddrive is full. --- name: prune # Prune ```no-highlight *$ docker system prune WARNING! This will remove: - all stopped containers - all networks not used by at least one container - all dangling images - all build cache ``` ??? - Be careful running this in Prod - Consider labeling your containers - Some run this and complain that their drives are still full -- What this doesn't clean by default: - Running containers (and their logs) - Tagged images - Volumes --- # Prune - YOLO ```no-highlight $ docker run -d --restart=unless-stopped --name cleanup \ -v /var/run/docker.sock:/var/run/docker.sock \ docker /bin/sh -c \ "while true; do docker system prune -f; sleep 1h; done" ``` ??? - If you're going to ignore all my words of caution, here's how you can automate the accidental deletion of data. - Tip from Bret Fisher - I call this YOLO for a reason - Be careful since this removes stopped containers and untagged images - I've had it delete DTR containers that didn't restart automatically - Untagged images includes your build cache -- ```no-highlight $ docker service create --mode global --name cleanup \ --mount type=bind,src=/var/run/docker.sock,\ dst=/var/run/docker.sock \ docker /bin/sh -c \ "while true; do docker system prune -f; sleep 1h; done" ``` ??? - We can automate the accidental deletion of data across an entire swarm cluster with a similar command. - The mode is global to run on every node - The mount flag had to be split across two lines for the slides but that's one long argument --- template: impact name: logs .content[ # Container Logs ] ??? - One thing that prune doesn't clean are container logs - If you have long running containers, they can fill your disk --- template: terminal <asciinema-player src="code-logs1.cast" cols=90 rows=24 preload=true font-size=18></asciinema-player> ??? - Here's an app that generates lots of logs - Those logs are stored as json in the container folder, by default - There is no size limit, by default - Docker logs to per container json files by default, without any limits - Rotating yourself could break that json formatting - Anyone here ever write a multi-threaded app and forget to lock the shared data before you modify it? - Luckily "without any limits" is just the default... we can change that --- template: terminal <asciinema-player src="code-logs2.cast" cols=90 rows=24 preload=true font-size=18></asciinema-player> ??? - Lets run that same example with a few extra options - max-size limits the size of each of these json log files - max-file limits the number of json files - Once the limit is hit, the last file is deleted, note the inodes - Json adds some overhead, note the size of the contents of the logs at the bottom compared to the json file size, looks like a 50% overhead --- template: terminal <asciinema-player src="code-logs3.cast" cols=90 rows=24 preload=true font-size=18></asciinema-player> ??? - In 18.09, docker added the local logging driver - This stores the logs in a different place, docker would prefer if you don't access this directly, they reserve the right to move things - The file format is different, they use protobuf, that means you probably won't be parsing it with a log forwarder to ELK or Splunk - Protobuf is much more efficient, more like 25% overhead - Rotating the logs also results in a gzip - End result of protobuf + gzip is more logs per 10M file get stored in less space on disk --- # Clean Your Logs ```no-highlight $ cat docker-compose.yml version: '3.7' services: app: image: sudobmitch/loggen command: [ "150", "180" ] * logging: * options: * max-size: "10m" * max-file: "3" ``` ??? - In case you don't run containers by hand, you can set these flags in a compose file - That's a lot of typing to do per service the compose file. What if we had a dozen services? --- # Clean Your Logs ```no-highlight version: '3.7' *x-defaults: * service: &default-svc image: sudobmitch/loggen logging: { options: { max-size: "10m", max-file: "3" } } services: cat: * <<: *default-svc command: [ "300", "120" ] environment: { pet: "cat" } turtle: * <<: *default-svc labels: { name: "gordon", levels: "all the way down" } ``` ??? - Docker added extension fields in 3.4. That's the `x-*` at the top level - Yaml always had an anchor/alias syntax - `&default-opts` is an anchor - `*default-opts` is an alias - `<<` merges in a set of keys from the alias - Hopefully many of you are thinking about how to use this for more than just logs, repetition inside docker-compose.yml files happens a lot, and we have the tools to make them DRY - The other reason I hope your thinking about how to use this in different ways is because we don't need this for logging... we can change docker's default behavior... --- template: terminal <asciinema-player src="code-logs4.cast" cols=90 rows=24 preload=true font-size=18></asciinema-player> ??? - We can change the default in the /etc/daemon.json file --- # Clean Your Logs - Best option to prevent container logs from filling disk space ```no-highlight $ cat /etc/docker/daemon.json { "log-opts": {"max-size": "10m", "max-file": "3"} } $ systemctl reload docker ``` ??? - Does not effect already running containers - Can be overridden per container - Docker engine does need to be reloaded to take effect --- template: picture .pic-80[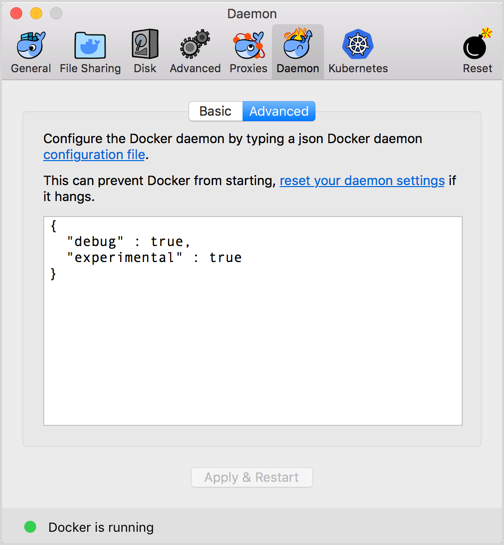] ??? - This isn't just advice for the Linux server admins, you can configure the daemon.json file on MacOS --- template: picture .pic-80[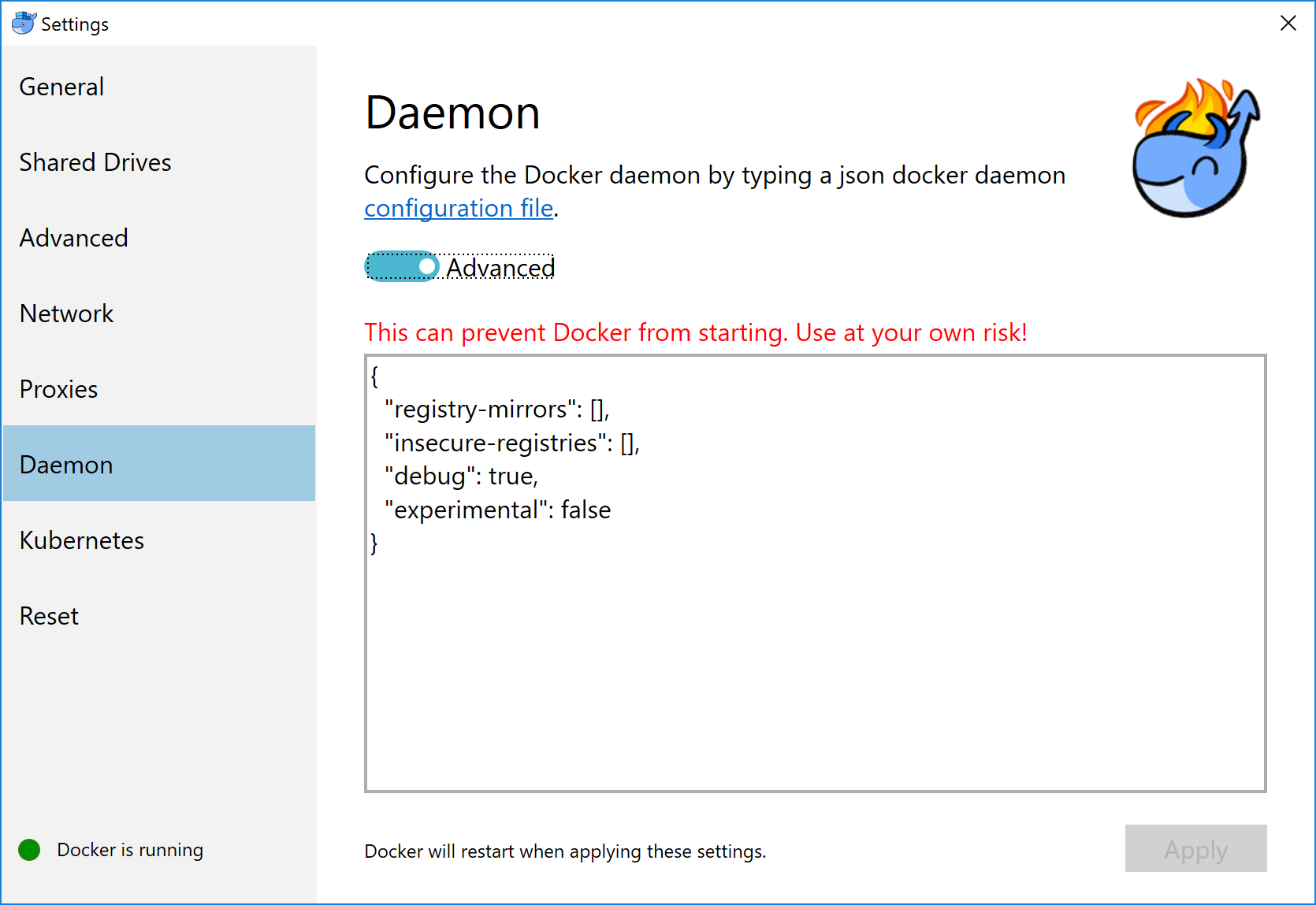] ??? - And windows users have the same option, Daemon -> Advanced --- template: impact .content[ # Networking ] ??? - So we just automated the fix to full disks and shrunk our yml templates, I may have automated myself out of a job, is anyone hiring? - J/K this isn't recruiter networking - This isn't the hallway track either - Though I will have a hallway track session after this at 5pm --- name: address-pools # Subnet Collisions - Docker networks sometimes conflict with other networks ??? - This happens especially when our laptops are moving, coffee shop, connecting to VPN's, or in prod where docker gets connected to the rest of the network after passing all the compliance tests. -- - Originally we had the BIP setting ```no-highlight $ cat /etc/docker/daemon.json { "bip": "10.15.0.1/24" } ``` ??? - The "bip" controls the default bridge network named "bridge" - Containers not attached to a specific network default here - Important tip: the gateway is assigned the IP address, so don't end with .0, give it a number inside the range like .1 or .254 for this class C example - But most of us create networks for our containers, and those networks get their own IP's, how do we define their subnets?... --- # Subnet Collisions - Default address poll added in 18.06 ```no-highlight $ cat /etc/docker/daemon.json { "bip": "10.15.0.1/24", "default-address-pools": [ {"base": "10.20.0.0/16", "size": 24}, {"base": "10.40.0.0/16", "size": 24} ] } ``` ??? - The default address pool controls new networks you create dynamically - Without this you'd need to manage the subnets yourself - This is also being added to `docker swarm` commands for overlay networks... --- # Subnet Collisions ```no-highlight $ docker swarm init --help ... --default-addr-pool ipNetSlice --default-addr-pool-mask-length uint32 ``` ??? - This was just added in 18.09 - Swarm mode has these options when you init the swarm -- ```no-highlight $ docker swarm init \ --default-addr-pool 10.20.0.0/16 \ --default-addr-pool 10.40.0.0/16 \ --default-addr-pool-mask-length 24 ``` ??? - To set more than one pool, pass the flag multiple times - I have an open PR to get these modifiable with `docker swarm update` --- name: netshoot # Network Debugging - Debugging networks from the host doesn't see inside the container namespace - Debugging inside the container means installing tools inside that container ??? - So we can now run our containers as home, work, and the coffee shop - But next we want to debug the network, and none of our network debugging tools understand the namespaced networking. If you check for open ports on the host, that doesn't help us debug what's happening inside the container's network namespace. -- - Networks in docker come in a few flavors: bridge, overlay, host, none - You can also configure the network namespace to be another container ??? - The trick to debugging in a network namespace comes down to the types of docker networks, you probably know bridge, overlay, and host - The "container" network type attaches one container to another's namespace - K8s people know this as pod networking --- template: terminal <asciinema-player src="code-netshoot.cast" cols=90 rows=24 preload=true font-size=18></asciinema-player> ??? - Lets start an nginx container and debug it - Nicolaka, Nicola Kabar, is a docker employee that put together this networking troubleshooter container, it contains loads of common tools - The `ss` command here is the replacement for `netstat`, we're showing that inside the network namespace for the nginx container, there is something listening on port 80 - We can do more than just `ss`, here's an example of tcpdump --- # Network Debugging ```no-highlight $ docker run --name web -p 9999:80 -d nginx *$ docker run -it --rm --net container:web \ nicolaka/netshoot ss -lnt State Recv-Q Send-Q Local Address:Port Peer Address:Port LISTEN 0 128 *:80 *:* ``` ??? - Nothing was ever installed in nginx, but we were able to use all of our network debugging tools as if we were in the same network - We can also use this to test connections between containers over docker networking, e.g. ping, curl, nslookup, etc, as one container talking to another, to know if the issue is our application or our network configuration --- name: layers template: impact .content[ # Layered Filesystem ] ??? - The layered filesystem in docker is a black box to many --- template: terminal class: center <asciinema-player src="code-layer1.cast" cols=100 rows=26 preload=false font-size=17></asciinema-player> ??? Step 1: layers as hashes - Lets take an example image built on top of a golang base image - I've already got the build cached, so that's fast for the slides - Lets inspect the image and look at ".RootFS.Layers" in both the golang base image and built golang-hello image to see some sha256 references - Note how all 7 of the layers from golang, from "fb" to "3c" are identical in the built image. - Docker doesn't copy these layers, they are pointers to the same bits on the filesystem. - When we push/pull an image, or build a new image, we only create layers that we don't already have. - We can only add new layers. - But what's inside of each of these layers? --- template: terminal class: center <asciinema-player src="code-layer2.cast" cols=100 rows=26 preload=false font-size=17></asciinema-player> ??? Step 2: image history - We can use a `docker image history` command to look at each step used to create any image. - This includes the disk space for each command, the command run (truncated by default, and left that way for these slides), when it was built. - You can read the history from the bottom to the top, and see the layers of the base debian image, golang, and then the golang-hello image we made - The "go build" added 48 megs of files, what's in there? - Each "chmod", "chown" command added 9MB, identical to the "cp" command. So flipping any bit, even some metadata on a file, causes an entire file copy apparently. - We can also see the "rm" command made a 0 byte difference, not negative, so did we save any disk space? - This also shows just the commands used to create a layer, but what about the files inside of that layer? --- template: terminal class: center <asciinema-player src="code-layer3.cast" cols=100 rows=26 preload=false font-size=17></asciinema-player> ??? Step 3: container diff - I ran a build with "--rm=false --no-cache" which leaves behind lots of temporary containers. Normally there is a "removing intermediate container" line on each step of that build. - The "Running in" lines show each of the container id's - What do all these containers get us, other than something else to cleanup with a system prune command? - We can run a "docker container diff" on any of those containers to see the changes. - The first character identifies the filesystem action, C for change, A for add, D for delete - Lots of files are created in /go/pkg/mod and /root/.cache/go-build, and then real fast you can see /src/app gets created - Lets look at that chown command, the 2c8 container, it does a "C" for change so the entire file gets copied. - The rm command on the af7 container does a "D" for delete, but note that the files we deleted still exist in the previous layers, so they are stored on disk, in the registry, we just don't see them once we apply this layer. - There's a reason I call this Dockerfile "bad", we are being very inefficient with our layers. --- # Understanding Layers ```no-highlight $ docker image build --rm=false --no-cache . $ docker container diff ... ``` - If you create a temporary file in a step, delete it in that same step - Look for unexpected changes that trigger a copy-on-write, e.g. permissions - Merge your `RUN` commands together ??? - Prior to 18.06, `chmod` and `chown` would trigger CoW even without permission/owner changes, all it took was a timestamp change - For diff, Docker looks at mode, uid, gid, rdev (special file, device with mknod) - And if not a directory, it also checks: mtime and size - Last bullet needs a plant from the audience saying: "Wait, what, how? You can't do that!" --- # From Bad ... ```no-highlight FROM golang:1.11 RUN adduser --disabled-password --gecos appuser appuser WORKDIR /src COPY . /src/ RUN go build -o app . WORKDIR / RUN cp /src/app /app RUN chown appuser /app RUN chmod 755 /app RUN rm -r /src USER appuser CMD /app ``` --- # ... to Okay ```no-highlight FROM golang:1.11 RUN adduser --disabled-password --gecos appuser appuser COPY . /src/ RUN cd /src \ && go build -o app . \ && cd / \ && cp /src/app /app \ && chown appuser /app \ && chmod 755 /app \ && rm -r /go/pkg /root/.cache/go-build /src USER appuser CMD /app ``` ??? - We simply escape the linefeed on each run command, and join the commands with the `&&` so that any error immediately stops the RUN - The downside of this is now our builds take longer if we change something in the middle of a long chain of commands in a RUN line --- template: terminal class: center <asciinema-player src="code-layer4.cast" cols=100 rows=26 preload=false font-size=17></asciinema-player> ??? Step 4: reorganize RUN commands - When we build this image - From the "okay" dockerfile - We can compare image sizes from the base golang image at 757MB to each of the built golang-hello images 833MB to now 766MB - When you do that math, that's going from 76MB to 9MB - The one thing I didn't do was merge the COPY and RUN commands, but we'd like to do that so that `rm -r /src` had an effect, we'll talk about that in a few --- template: terminal class: center <asciinema-player src="code-layer5.cast" cols=100 rows=26 preload=false font-size=17></asciinema-player> ??? Step 5: Alpine base - We can do even better than that by switching to a smaller base image based on Alpine - When we compare the disk for these, the v3 image at 335MB added 24MB to the 311MB golang-alpine base image, that's because we needed to install tools that alpine doesn't ship with, like git. - But the overall image at 335MB is less than half the size of the debian based golang build at 766MB. - And if we rerun builds like this, the initial steps to install git are cached and reused, getting us back down to that 9MB delta between builds. - We are still shipping the compiler, git, etc needed to build our app - All we want is the runtime environment, not the compile environment, most of us know that as multi-stage --- # Multi-stage Builds - Everything you know about making efficient images is now wrong - The compile of our code should be layer inefficient to be cache efficent - Only the released stage needs to be layer efficient ??? - Layer inefficient and cache efficient means you can break up those RUN lines so docker can start the build with as many cached layers as possible - Only join run steps where you don't want a cache split, like `apt update` and `apt install` - Previously highly efficient images may install a compiler, build tools, run the compile, uninstall all those tools, in a single step - Now we: - install our compiler once, that gets cached and reused - run the compile, copy that compiled object to a runtime stage - don't bother cleaning up the compile tools and source code since the compile stage is not shipped --- ```no-highlight FROM golang:1.11-alpine as build RUN apk add --no-cache git ca-certificates RUN adduser -D appuser WORKDIR /src COPY . /src/ RUN CGO_ENABLED=0 go build -o app . FROM scratch as release COPY --from=build /etc/passwd /etc/group /etc/ COPY --from=build /src/app /app USER appuser CMD [ "/app" ] FROM alpine as dev COPY --from=build /src/app /app CMD [ "/app" ] FROM release ``` ??? - The resulting multi-stage dockerfile has multiple from lines, one for each stage or image being created - The initial stages are likely a compile step - Intermediate stages may be for developers, unit testing, code quality, security scanner, etc. - The final stage is the minimal release image - Sometimes the release stage is done early so tests can be run against that - Scratch is nothing, think `rm -rf /` or `format c:` for the windows users --- template: terminal class: center <asciinema-player src="code-layer6.cast" cols=100 rows=26 preload=false font-size=17></asciinema-player> ??? Step 6: multi-stage - We run the same build, and here's the Dockerfile from the previous slide - The resulting image is now 9MB, down from over 800MB when we started - When we look at the history, we don't see anything from a base image since scratch is nothing, no go compiler, no alpine or other filesystem - That's good if you can statically compile a binary without any external dependencies - But even if you have Java, you can compile the JAR with a JDK and Maven and run with just a JRE as your release image - So multi-stage is awesome! ... --- template: inverse .content[ # "Hold my beer."<br><br> --BuildKit ] --- name: buildkit # BuildKit Features For Everyone - GA in Docker 18.09 - Context only pulls needed files that have changed from previous builds - And it only pulls files you ADD or COPY, not the entire context folder - Multi-stage builds use a dependency graph - Cache from a remote registry - Cache pruning has options for age and size to keep ??? - Context is effectively an rsync - Dependency graph means buildkit only builds stages needed to get to the target. If you have a multi-stage build with a test stage in the middle, buildkit will likely skip right over that stage. - You can always explicitly build any target - Caching from a registry is useful for temporary build environments (cloud) --- # BuildKit Cache Pruning ```no-highlight $ docker builder prune --keep-storage=1GB --filter until=72h ``` ??? - The until time looks at how long cache entries have been unused - When you pass both options, only cache entries that fail both are deleted -- ```no-highlight $ cat /etc/docker/daemon.json { "builder": { "gc": { "enabled": true, "policy": [ {"keepStorage": "512MB", "filter": ["unused-for=168h"]]}, {"keepStorage": "30GB", "all": true} ] } } } ``` ??? - What's really cool about the BuildKit cache is you can configure automatic garbage collection in the daemon.json file. - The first line says if I have over 512MB of cache that is unused for over a week, and the second line lets you have up to 30GB of cache total --- # BuildKit Experimental Features - Change your frontend to any parser you want, implemented with a Docker image - Bind Mounts, from build context or another image - Cache Mounts, similar to a named volume - Tmpfs Mounts - Build Secrets, file never written to image filesystem - SSH Agent, private Git repos ??? - You can build your own Dockerfile parser, it's just an image - The parser itself is a `# syntax=` line at the top of the Dockerfile - "Parser directive" in Dockerfile notation - Change the parser, per image, add new features to old docker engine - Other bullets are a `RUN --mount` command, mounted directories do not get included in the image. - Bind: to context or image, microscanner, large data processing - Cache: Maven's m2, Golang module and git cache, apt package download, npm, all saved from previous builds - Secrets: ssh key, aws credentials, injected as a file that doesn't get written to image - SSH: if your key is password protected, use ssh-agent --- ```no-highlight *# syntax=docker/dockerfile:experimental FROM golang:1.11-alpine as build RUN apk add --no-cache git ca-certificates tzdata RUN adduser -D appuser WORKDIR /src COPY . /src/ *RUN --mount=type=cache,id=gomod,target=/go/pkg/mod/cache \ * --mount=type=cache,id=goroot,target=/root/.cache/go-build \ CGO_ENABLED=0 go build -o app . USER appuser CMD ./app ``` ??? - Note the first line, that is not a comment, it's a parser directive that is used by buildkit to change the frontend parser - The RUN command has two cache mounts, these are the same two directories we saw in the diff output before - Once you start using experimental features, you won't be building this image without BuildKit, those `--mount` args are not supported by the classic build --- template: terminal <asciinema-player src="code-buildkit.cast" cols=100 rows=26 preload=true font-size=17></asciinema-player> ??? - Lets compare BuildKit on bottom to Multi-stage on top - I've already run the build in both environments once so everything is cached - These are two different DinD instances, hence the different port numbers - We change a single dependency and rebuild our app - I give the classic build a short head start, it's already downloading dependencies before we kickoff buildkit - If you look really fast, you may notice build kit runs stuff out of order, and I'm pretty sure concurrently, downloading different prereq images, etc. - BuildKit still finishes first, it was extracting dependencies rather that fetching them, that's because the modules were mounted from the last time we ran the build with the `--mount` syntax - And eventually you see the classic build finishes downloading dependencies --- # Enable BuildKit ```no-highlight $ export DOCKER_BUILDKIT=1 $ docker build -t your_image . ``` ??? - To run BuildKit, you just export an environment variable and build like normal -- ```no-highlight $ cat /etc/docker/daemon.json { "features": {"buildkit": true} } ``` ??? - Or to make BuildKit the new default, you can configure the daemon.json with the above "features" setting - Support for tools like docker-compose is being worked on. - Build with `docker build` in CI or a script anyway. - Even without experimental features like `--mount`, the backwards compatible changes are worth the upgrade: pulling only the parts of the context that changed and are needed, dependency graph for multi-stage builds, remote registry caching, and improved cache pruning --- template: impact .content[ # Volumes ] --- name: volume-local # Local Volume Driver .center[.pic-80[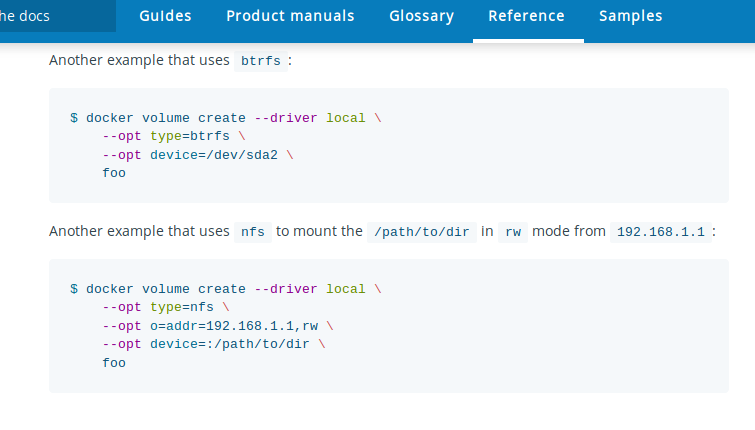]] ??? - From Docker's documentation, we have steps to mount things like btrfs and nfs with the local volume driver - Nice thing is that this works out of the box, no 3rd party driver install required - Looking at the syntax, it's very similar to the mount command - The mount command is mostly a frontend to the mount syscall - The local volume driver is also mostly a pass through to the mount syscall - With nfs, you typically pass a device "addr:/path" to the command, vs the syscall which passes a device ":/path" with an option "addr" - To run a mount syscall, we need a type, source device, options, and target - With NFS, we can create a volume with better options than just this example... --- # NFS Mounts ```no-highlight $ docker volume create \ --driver local \ --opt type=nfs \ --opt o=nfsvers=4,addr=nfs.example.com,rw \ --opt device=:/path/to/dir \ foo ``` ??? - The local driver is the default, I'm being explicit here - Type is "nfs", this can be any fs type supported by the host, ext4, ntfs, etc - Option "o" are additional options, comma separated, that you'd pass to mount - Addr gets DNS resolved when type is NFS by Docker - RW is read-write - NFS ver is set to 4 here, instead of using the type "nfs4" to get DNS on ADDR - If you do not set the NFS version, Linux goes through the different versions - Device in NFS is just the remote path, with a preceding colon - That's what the mount syscall looks like after the NFS mount command moves the IP to the addr option - Note: the remote directory does need to exist! - But what if we don't want to create a volume?... --- # NFS Mounts ```no-highlight $ docker container run -it --rm \ --mount \ type=volume,\ dst=/container/path,\ volume-driver=local,\ volume-opt=type=nfs,\ \"volume-opt=o=nfsvers=4,addr=nfs.example.com\",\ volume-opt=device=:/host/path \ foo ``` ??? - For Docker Run, we have the `--mount` syntax, similar to `-v` - It is more explicit / verbose - Allows different volume driver options for different mounts in the same container - All of this is one long argument, the parameter string is comma separated, I've only broken it across lines for the slides - The mount syntax also identical to the service create syntax which doesn't support `-v`... --- # NFS Mounts ```no-highlight $ docker service create \ --mount \ type=volume,\ dst=/container/path,\ src=foo-nfs-data,\ volume-driver=local,\ volume-opt=type=nfs,\ \"volume-opt=o=nfsvers=4,addr=nfs.example.com\",\ volume-opt=device=:/host/path \ foo ``` ??? - Lets look at these parameters... - Type can be volume, bind, or tmpfs - DST or Target is where to mount the directory inside the container - SRC or Source is the volume name for named volumes, host dir for bind, or empty for anonymous volume - With volume type, driver is any volume driver you want - And then we have type, device, and "o" as before - Note that `--mount` is comma separated as is opt `o`, so we need to quote that entire section of the command, and escape those quotes from the bash shell --- # NFS Mounts ```no-highlight version: '3.7' volumes: nfs-data: driver: local driver_opts: type: nfs o: nfsvers=4,addr=nfs.example.com,rw device: ":/path/to/dir" services: app: volumes: - nfs-data:/data ... ``` ??? - Everything we did in a volume create has a mapping to the compose file - This is all you need to run an HA service in swarm with persistent data if you have HA storage available over NFS - What else can we mount?... --- # Other Filesystem Mounts ```no-highlight version: '3.7' volumes: ext-data: driver: local driver_opts: type: ext4 o: ro device: "/dev/sdb1" services: app: volumes: - ext-data:/data ... ``` ??? - If you have data on an ext4 or other drive, mount it directly into the container without first mounting it on the host - Options let you make it read-only --- # Other Filesystem Mounts ```no-highlight version: '3.7' volumes: proc: driver: local driver_opts: type: proc device: proc services: app: volumes: - proc:/ext-proc ... ``` ??? - You could mount proc from the host, outside of the container namespacing - This would be bad, but you can do it --- # Overlay Filesystem as a Volume ```no-highlight version: '3.7' volumes: overlay-data: driver: local driver_opts: type: overlay device: overlay o: lowerdir=${PWD}/data2:${PWD}/data1,\ upperdir=${PWD}/upper,workdir=${PWD}/workdir services: app: volumes: - overlay-data:/data ... ``` ??? - You can make your own overlay filesystem and mount that into a container - lowerdir is the same as docker image layers, RO - upperdir is where RW changes go for this volume mount, others could point to the same lowerdir with a different upperdir - workdir is a temp directory needed by overlay, just give it something empty - This lets you have an unchanging base data, useful for a CI pipeline that resets to a known initial state while still letting the container write to the volume - Note the `o:` option is one long line, I had to split it for the slides --- name: volume-bind # Named Bind Mount ```no-highlight version: '3.7' volumes: bind-test: driver: local driver_opts: type: none o: bind device: /home/user/test services: app: volumes: - "bind-test:/test" - "./test2:/test2" ... ``` ??? - Similar to host mount but named bind mount: - Can be anywhere, not just /var/lib/docker/volumes/.. - Device directory must already exist, mount will not create it - Initializes an empty directory on the host the contents of the image - Includes uid/gid and permissions of those files - Useful to extract data from the image to the developer machine --- template: inverse # That's nice, but I just use:<br> $(pwd)/code:/code<br><br> ??? - For developers on their laptops, you're not doing NFS mounts, they don't want to extract data, they want to inject source code to speed up their workflow - Let me stop you there, don't run that... --- template: inverse # That's nice, but I just use:<br> ~~$(pwd)/code:/code~~ <br> "$(pwd)/code:/code" ??? - If you use `$(pwd)` put it in quotes, otherwise a space in the path will give you weird errors - Lets talk about injecting data/source with a simple host volume --- name: fix-perms # Dockerfile for Java ```no-highlight FROM openjdk:jdk as build RUN apt-get update \ && apt-get install -y maven \ && useradd -m app COPY code /code RUN --mount=target=/home/app/.m2,type=cache \ mvn build CMD ["java", "-jar", "/code/app.jar"] USER app FROM openjdk:jre as release COPY --from=build /code/app.jar /app.jar CMD ["java", "-jar", "/app.jar"] ``` ??? - Lets take a Java example, even using BuildKit with the M2 directory mounted - Ops wants to make our container more secure by configuring it to run as a non-root user --- # Developer Compose File ``` version: '3.7' volumes: m2: services: app: build: context: . * target: build image: registry:5000/app/app:dev * command: "/bin/sh -c 'mvn build && java -jar /code/app.jar'" volumes: * - ./code:/code * - m2:/home/app/.m2 ``` ??? - Devs want to go even faster, they don't want to rebuild the entire image for every change. This is even more relevant for the live updating code. - The build targets the first stage "build" with its full jdk and maven. - We override "command" to run a maven build first. - And we mount our code as a host volume and even cache m2 so all we need to do is restart this container to pickup any changes. - And when the developer runs that, they get... --- # Problem with the Developer Workflow ```no-highlight Error accessing /code: permission denied ``` -- - UID for `app` inside the container doesn't match our UID on the host ??? - Linux bind mounts are at a UID level, without any mapping. User names are added on top of that, not unlike DNS names added on top of IP addresses. - When the UID in the container doesn't match our UID on the host, we often get permission errors. -- - Unless you're on MacOS or VirtualBox ??? - Docker for Mac has OSXFS, VirtualBox does something similar, the file owner inside the container is automatically mapped to your MacOS user outside of the VM - If you only develop on those platforms, then you can ignore this next bit unless you ever want to do something like mount the docker socket which is inside the VM rather than being mounted from the host. --- # Fixing UID/GID Possible solutions: - Run everything as root - Change permissions to 777 - Adjust each developers uid/gid to match image - Adjust image uid/gid to match developers - Change the container uid/gid from `run` or `compose` ??? - There's an error on this slide... --- # Fixing UID/GID Possible **bad** solutions: - Run everything as root - Change permissions to 777 - Adjust each developers uid/gid to match image - Adjust image uid/gid to match developers - Change the container uid/gid from `run` or `compose` ??? - If you run things as root, or open permissions for everyone to have full access, expect to get hacked. - Trying to get every developers laptop to have the same UID is painful, if not impossible. - Making a new image per developer goes against any concept of portability and reusability. - Last option is really close, requires scripting to deploy our image to lookup the UID/GID, but doesn't change files in the image outside of our volume -- Another solution: - "Use a shell script" - Some Ops Guy --- template: inverse # Disclaimer The following slide may not be suitable for all audiences ??? - Those developers that are disturbed by shell scripts may want to turn away for this next slide --- # Fixing UID/GID ```no-highlight # update the uid if [ -n "$opt_u" ]; then * OLD_UID=$(getent passwd "${opt_u}" | cut -f3 -d:) * NEW_UID=$(stat -c "%u" "$1") if [ "$OLD_UID" != "$NEW_UID" ]; then echo "Changing UID of $opt_u from $OLD_UID to $NEW_UID" * usermod -u "$NEW_UID" -o "$opt_u" if [ -n "$opt_r" ]; then * find / -xdev -user "$OLD_UID" -exec chown -h "$opt_u" {} \; fi fi fi ``` ??? - This is part of a `fix-perms` shell script I package into my base image - The first highlighted line gets the UID of the user inside the container - The second highlight gets the UID of the file or directory mounted as a volume - If those two UID's do not match, **I change the container to match the host** with the `usermod` - And after running that `usermod`, I run a `chown` on any files still owned by the old UID inside the container --- # Fixing UID/GID ```no-highlight FROM openjdk:jdk as build *COPY --from=sudobmitch/base:scratch / / RUN apt-get update \ && apt-get install -y maven \ && useradd -m app COPY code /code RUN --mount=target=/home/app/.m2,type=cache \ mvn build *COPY entrypoint.sh /usr/bin/ *ENTRYPOINT ["/usr/bin/entrypoint.sh"] CMD ["java", "-jar", "/code/app.jar"] USER app ``` ??? - I've packaged the above script and some other utilities into a base image that can be used to extend your image with a `COPY --from` - And then I included an entrypoint.sh script... --- # Fixing UID/GID ```no-highlight #!/bin/sh if [ "$(id -u)" = "0" ]; then # running on a developer laptop as root fix-perms -r -u app -g app /code exec gosu app "$@" else # running in production as a user exec "$@" fi ``` ??? - That entrypoint checks if I'm root, and if so, fixes the /code permissions to match the app container uid - Then I have this `exec gosu` that drops from `root` to the `app` user and runs the cmd - In prod where I don't run as root, and have matched the prod uid's to match the image, this gets skipped and I exec the command - The end result is the cmd is running as the user as pid 1, all evidence of the entrypoint is gone from the process list, making it transparent --- # Developer Compose File ```no-highlight version: '3.7' volumes: m2: services: app: build: context: . target: build image: registry:5000/app/app:dev command: "/bin/sh -c 'mvn build && java -jar /code/app.jar'" * user: "0:0" volumes: - ./code:/code - m2:/home/app/.m2 ``` ??? - The developer compose file is the same as before with one addition, the user is set to root. - The production compose file wouldn't have any of this, use the release image with the JRE instead of JDK, and no other settings. - Prod will run as default app, with no volume mounts, build, or cmd. --- # Production Compose File ```no-highlight version: '3.7' services: app: image: registry:5000/app/app:${build_num} ``` ??? - The important part about production is what isn't in the file - Not running as root, not mounting a volume, not overriding the command - Also the build runs from CI/CD, and we just deploy the build number --- # Fixing UID/GID Developers: - Run the container entrypoint as root - Mount their code as `/code` from the host - Entrypoint inside the container updates `app` user to match uid of `/code` - Entrypoint switches from root to app and runs container command with `exec` - Pid 1 is the app with a uid matching the host - Reads and writes to `/code` happen as the developers uid Production: - Runs the same image without root or a volume - Entrypoint skips `fix-perms` and `gosu` --- layout: false class: title name: thanks # Thank You ### github.com/sudo-bmitch/presentations<br> github.com/sudo-bmitch/docker-base .content[ .left-column[ .pic-80[] ] .right-column[.align-right[.no-bullets[ <br> - Brandon Mitchell - Twitter: @sudo_bmitch - GitHub: sudo-bmitch ]]] ] ??? - I hope this was useful - If we have time for questions, please use a mic - If you missed a picture of any slide, these are all online in the presentations repo, send me PR's for any typos - Docker-base contains the fix-perms script and several other useful utilities - I have a hallway track at 5pm where we can discuss building efficient images, buildkit, multi-stage, entrypoints, etc